Edinburgh MRI modelled speech corpus
MRI recordings on the STAR resource were created with funding from the Royal Society of Edinburgh and with the financial support of NHS Research Scotland (NRS), through Edinburgh Clinical Research Facility.
Recording MRI
The MRI recordings on this website were recorded at Edinburgh University’s Edinburgh Imaging Facility RIE (Figure 1) using a 3 Tesla Siemens Prisma MRI scanner.. Recording protocols were developed by MRI Physicist Dr Michael Thrippleton. MRI data acquisitions were carried out by MRI Research Radiographer Charlotte Jardine, and the clinical recording team at the Edinburgh Imaging Facility RIE.

Figure 1: Edinburgh Imaging Facility RIE.
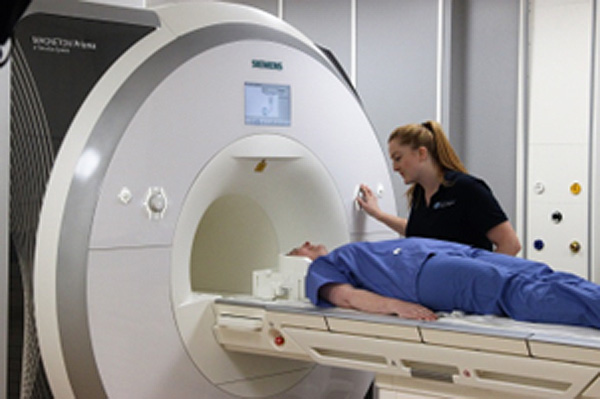
Figure 2: Edinburgh Imaging Facility RIE, Siemens Prisma MRI scanner.
Frame rate and editing
The MRI recording protocol produced c6.25 mid-sagittal head scans per second, which were saved in medical DICOM image format, converted into avi video format using ImageJ software (Rasband 1997-2014) with an image resolution of 320x320 pixels. Image brightness/contrast adjustment and subtitling was carried out using VirtualDub (Lee, 1998).
Stimuli
Stimuli were International Phonetic Association and extended International Phonetic Association symbols and English minimal word sets, arranged as a power-point presentation and presented to the participant via a screen.
Recording audio and resynchronising audio and video
We used an OptoAcoustics FOMRI III dual-channel, fibre-optic microphone system (Figure 3) to record speech inside the MRI machine. As well as containing no metal parts and being safe to use in an MRI machine, this microphone and associated software have a built-in noise-cancelling system to reduce noise generated by the MRI machine from the acoustic signal. Sound is captured by two microphones – one pointing towards the speaker’s mouth and covered by a pop-shield, while the other is directed away from the speaker to gather the ambient noise inside the MRI machine. The OptiMRI software uses the recording from the upper microphone to help remove noise produced by the MRI machine. The microphone was fixed to the head coil using velcro and the microphone was positioned as close as possible to the speaker’s lips using the microphone’s goose neck.
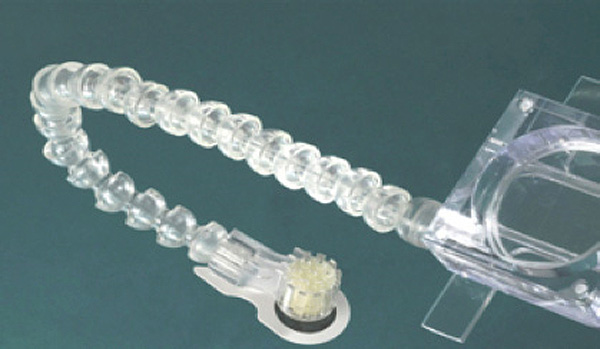
Figure 3: Fibre-optic, noise-cancelling microphone used to record speech inside the MRI machine
Further noise-cancelling was carried out using Audacity (Audacity Project 2005) and Praat (Boersma, Paul & Weenink, David 2013); however, it was not possible to completely remove extraneous noise relating to the MRI machine without removing too much of the speech signal. For the purposes of the STAR resource, that is, to exemplify speech sounds, we opted to use “clean” audio that matched the MRI videos by having our model talker match her productions in the MRI machine, while in a sound studio. We used denoised MRI audio recordings as stimuli for our model talker to copy while being recorded with ultrasound tongue imaging. We also examined the lingual articulation in the MRI and the UTI recording to make sure that they were comparable.
References
Audacity Project. (2005). Audacity. 2.0.5 ed. Pittsburgh: Pittsburgh Carnegie Mellon University, October 21, 2013,.
Baer, T., Gore, J.C., Boyce, S. and Nye, P.W. (1987). Application of MRI to the analysis of speech production. Magnetic Resonance Imaging 5(1), 1-7.
Boersma, Paul & Weenink, David. (2013). Praat: doing phonetics by computer. 5.3.47 ed. http://www.praat.org/.
Lee, A. (1998) VirtualDub - Video processing and capture application. V1.10.4. https://www.virtualdub.org/
Rasband, W.S. 1997-2014. ImageJ. Bethesda, Maryland, USA: U. S. National Institutes of Health.